
介绍
LangChain 是一个用于开发由大型语言模型(LLMs)驱动的应用程序的框架。
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
- 开发:使用 LangChain 的开源构建块和组件构建您的应用程序。通过第三方集成和模板快速启动。
- 生产化:使用 LangSmith 检查、监控和评估您的链,以便您能够持续优化和自信地部署。
- 部署:使用 LangServe 将任何链转换为 API。
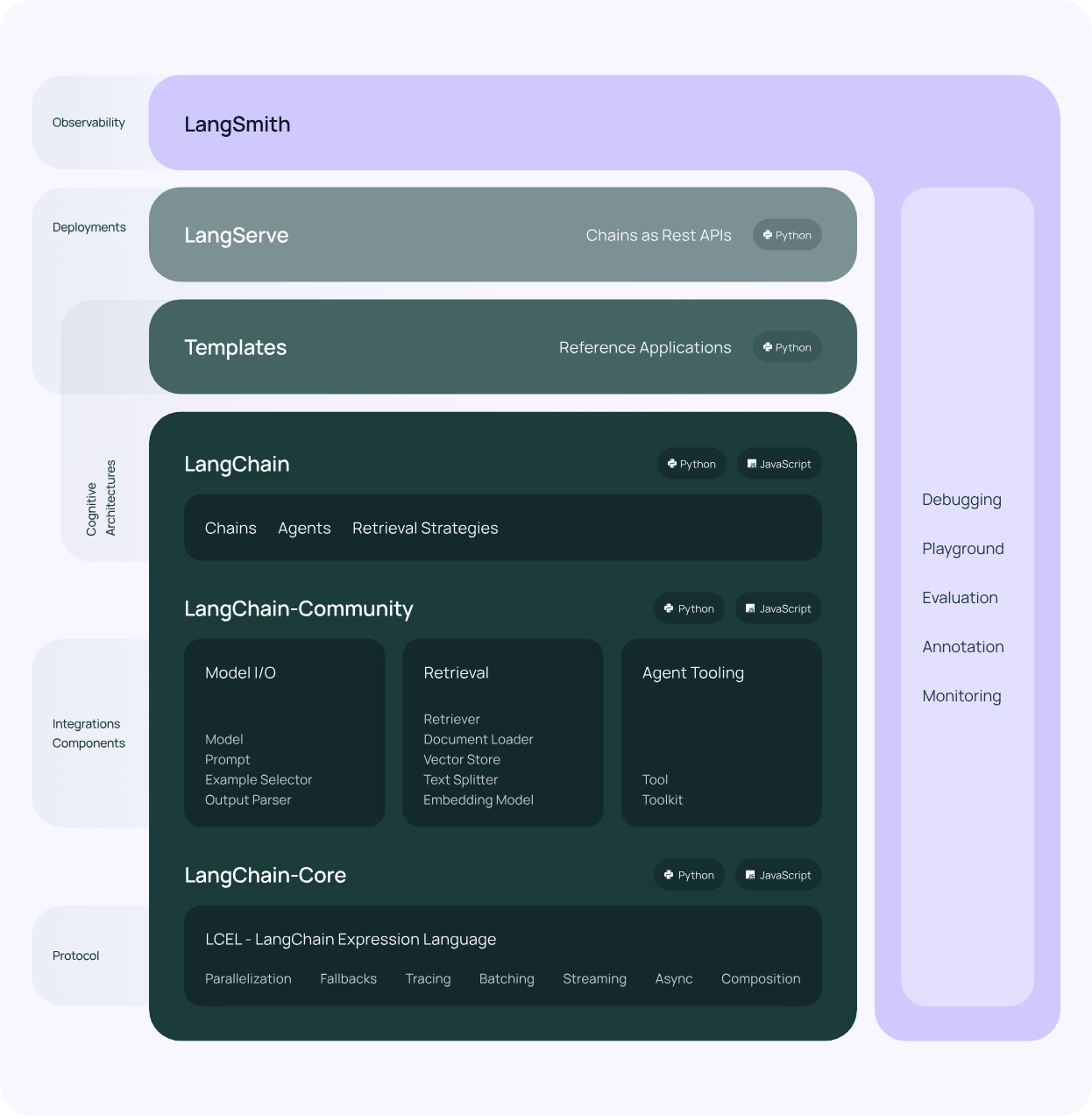
具体来说,该框架由以下开源库组成:
-
langchain-core:基础抽象和 LangChain 表达语言。 -
langchain-community:第三方集成。- 合作伙伴包(例如 langchain-openai、langchain-anthropic 等):一些集成进一步分拆为仅依赖于 langchain-core 的轻量级包。
-
langchain:构成应用程序认知架构的链、代理和检索策略。 -
langgraph: 图中的边和节点,使用 LLM 构建稳健和有状态的多角色应用程序。
-
langserve:将 LangChain 链部署为 REST API。
-
langSmith:一个开发者平台,让您调试、测试、评估和监控 LLM 应用程序。
注意 这些文档重点介绍 Python LangChain 库。点击这里查看 JavaScript LangChain 库的文档。
教程
如果您希望构建特定的内容或更喜欢动手学习,请查看我们的教程。这是开始的最佳地方。
这些是最好的入门教程:
构建一个简单的 LLM 应用程序 构建一个聊天机器人 构建一个代理 在这里探索完整的教程列表。
操作指南
在这里您会找到关于“如何……”类型问题的简短答案。这些操作指南不会深入涵盖主题——您会在教程和 API 参考中找到这些内容。然而,这些指南将帮助您快速完成常见任务。
概念指南
介绍您需要了解的所有关键 LangChain 部分!在这里,您会找到所有 LangChain 概念的高层次解释。
API 参考
前往参考部分以获取 LangChain Python 包中所有类和方法的完整文档。
生态系统
🦜🛠️ LangSmith
追踪并评估您的语言模型应用程序和智能代理,帮助您从原型转向生产环境。
🦜🕸️ LangGraph
使用 LLM 构建有状态的多角色应用程序,建立在 LangChain 原语之上(并旨在与其一起使用)。
🦜🏓 LangServe
将 LangChain 可运行对象和链部署为 REST API。
其他资源
安全性
阅读我们的安全最佳实践,确保您在使用 LangChain 开发时保持安全。
集成
LangChain 是一个丰富的工具生态系统的一部分,这些工具与我们的框架集成并在其基础上构建。查看我们不断增长的集成列表。
贡献
查看开发者指南,了解贡献的指导方针并帮助您设置开发环境。
学习指南
是否刚接触LangChain或LLM应用开发?阅读这些材料,快速入门。
基础知识
与外部知识协作
专门任务
有关更多教程,请参见我们的cookbook部分。
基础知识
使用LCEL构建一个简单的LLM应用
在这个快速入门教程中,我们将向您展示如何使用LangChain构建一个简单的LLM应用。这个应用将把文本从英语翻译成另一种语言。这是一个相对简单的LLM应用——只是一个单一的LLM调用加上一些提示。然而,这仍然是一个开始使用LangChain的好方法——只需一些提示和一个LLM调用就可以构建很多功能!
阅读本教程后,您将对以下内容有一个高层次的概览:
-
使用语言模型
-
使用PromptTemplates和OutputParsers
-
使用LangChain表达语言(LCEL)将组件链在一起
-
使用LangSmith调试和跟踪您的应用程序
-
使用LangServe部署您的应用程序
让我们开始吧!
设置
Jupyter Notebook
本指南(以及文档中的大多数其他指南)使用Jupyter notebooks,并假设读者也是如此。Jupyter notebooks非常适合学习如何使用LLM系统,因为很多时候事情可能会出错(输出意外,API宕机等),在交互环境中进行指南学习是更好地理解它们的好方法。
这个和其他教程或许在Jupyter notebook中运行最方便。请参见此处以获取安装说明。
安装
要安装LangChain,请运行:
- Pip
pip install langchain
- Conda
conda install langchain -c conda-forge
有关更多详细信息,请参见我们的 安装指南。
LangSmith
许多使用LangChain构建的应用程序将包含多个步骤和多次LLM调用。随着这些应用程序变得越来越复杂,能够检查链或代理内部发生的情况变得至关重要。最好的方法是使用LangSmith。
在上面的链接注册后,确保设置环境变量以开始记录跟踪信息:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
使用语言模型
首先,让我们学习如何单独使用语言模型。LangChain支持许多不同的语言模型,您可以互换使用——请选择您想使用的模型!
- OpenAI
pip install -qU langchain-openai
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4")
首先直接使用模型。ChatModels 是 LangChain “Runnables”的实例,这意味着它们提供了一个标准接口用于与其交互。要简单地调用模型,我们可以将消息列表传递给 .invoke 方法。
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
API 参考:HumanMessage | SystemMessage
AIMessage(content='ciao!', response_metadata={'token_usage': {'completion_tokens': 3, 'prompt_tokens': 20, 'total_tokens': 23}, 'model_name': 'gpt-4', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-fc5d7c88-9615-48ab-a3c7-425232b562c5-0')
如果我们启用了LangSmith,我们可以看到这个运行被记录到LangSmith,并且可以查看LangSmith trace。
OutputParsers
注意,模型的响应是一个AIMessage。它包含一个字符串响应以及关于响应的其他元数据。很多时候,我们可能只想处理字符串响应。我们可以使用一个简单的输出解析器来解析这个响应。
首先,我们导入简单输出解析器。
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
API 参考:StrOutputParser
一种使用方法是单独使用它。例如,我们可以保存语言模型调用的结果,然后将其传递给解析器。
result = model.invoke(messages)
parser.invoke(result)
'Ciao!'
更常见的是,我们可以将模型与这个输出解析器“链接”起来。这意味着每次在这个链中都会调用这个输出解析器。这个链接收语言模型的输入类型(字符串或消息列表),并返回输出解析器的输出类型(字符串)。
我们可以使用 | 运算符轻松创建这个链。| 运算符在LangChain中用于将两个元素组合在一起。
chain = model | parser
chain.invoke(messages)
'Ciao!'
如果我们现在查看LangSmith,我们可以看到这个链有两个步骤:首先调用语言模型,然后将其结果传递给输出解析器。我们可以查看LangSmith trace。
提示模板
目前,我们直接将消息列表传递给语言模型。那么,这个消息列表是从哪里来的呢?通常,它是由用户输入和应用程序逻辑的组合构建而成的。这个应用程序逻辑通常会将原始用户输入转换为一个准备传递给语言模型的消息列表。常见的转换包括添加系统消息或使用用户输入格式化模板。
提示模板(PromptTemplates)是LangChain中的一个概念,旨在帮助完成这种转换。它们接收原始用户输入并返回准备传递给语言模型的数据(提示)。
让我们在这里创建一个提示模板。它将接收两个用户变量:
- language: 要将文本翻译成的语言
- text: 要翻译的文本
from langchain_core.prompts import ChatPromptTemplate
API 参考:ChatPromptTemplate
首先,让我们创建一个字符串,我们将其格式化为系统消息:
system_template = "Translate the following into {language}:"
接下来,我们可以创建提示模板(PromptTemplate)。这将是系统模板(system_template)以及一个用于放置文本的简单模板的组合。
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
这个提示模板的输入是一个字典。我们可以单独使用这个提示模板来看看它的效果。
result = prompt_template.invoke({"language": "italian", "text": "hi"})
result
ChatPromptValue(messages=[SystemMessage(content='Translate the following into italian:'), HumanMessage(content='hi')])
我们可以看到它返回了一个包含两条消息的ChatPromptValue。如果我们想直接访问这些消息,可以这样做:
result.to_messages()
[SystemMessage(content='Translate the following into italian:'),
HumanMessage(content='hi')]
使用LCEL将组件链接在一起
现在,我们可以使用管道(|)操作符将其与上面的模型和输出解析器结合起来:
chain = prompt_template | model | parser
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
这是一个使用LangChain表达语言(LCEL)将LangChain模块链接在一起的简单示例。这种方法有几个好处,包括优化的流处理和跟踪支持。
如果我们查看LangSmith跟踪,我们可以看到所有三个组件都出现在LangSmith trace中。
使用LangServe进行服务
现在我们已经构建了一个应用程序,需要将其部署。这就是LangServe的用武之地。LangServe帮助开发者将LangChain链部署为REST API。你不需要使用LangServe来使用LangChain,但在本指南中,我们将展示如何使用LangServe部署你的应用程序。
虽然本指南的第一部分是打算在Jupyter Notebook或脚本中运行的,但现在我们将离开那个环境。我们将创建一个Python文件,然后从命令行与其交互。
安装方法:
pip install "langserve[all]"
服务器
为了为我们的应用程序创建一个服务器,我们将创建一个 serve.py 文件。这将包含我们用于服务应用程序的逻辑。它包括三部分内容:
- 我们刚刚构建的链的定义
- 我们的 FastAPI 应用
- 一个用于服务链的路由定义,这是通过
langserve.add_routes完成的
#!/usr/bin/env python
from typing import List
from fastapi import FastAPI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langserve import add_routes
# 1. Create prompt template
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages([
('system', system_template),
('user', '{text}')
])
# 2. Create model
model = ChatOpenAI()
# 3. Create parser
parser = StrOutputParser()
# 4. Create chain
chain = prompt_template | model | parser
# 4. App definition
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# 5. Adding chain route
add_routes(
app,
chain,
path="/chain",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
API 参考:ChatPromptTemplate | StrOutputParser | ChatOpenAI
就是这样!如果我们执行这个文件:
python serve.py
我们应该会看到我们的链在以下地址提供服务: http://localhost:8000。
Playground
每个 LangServe 服务都带有一个简单的内置用户界面,用于配置和调用应用程序,并提供流式输出和中间步骤的可见性。前往 http://localhost:8000/chain/playground/ 试试看吧!传入与之前相同的输入——{"language": "italian", "text": "hi"}——它应该会像之前一样响应。
客户端
现在让我们设置一个客户端,以便以编程方式与我们的服务进行交互。我们可以使用 langserve.RemoteRunnable 轻松实现这一点。使用这个工具,我们可以像在客户端运行一样与提供服务的链进行交互。
from langserve import RemoteRunnable
remote_chain = RemoteRunnable("http://localhost:8000/chain/")
remote_chain.invoke({"language": "italian", "text": "hi"})
'Ciao'
要了解有关 LangServe 的许多其他功能的更多信息,请访问 这里。
结论
就是这样!在本教程中,你已经学会了如何创建你的第一个简单的 LLM 应用程序。你学会了如何使用语言模型,如何解析它们的输出,如何创建提示模板,如何使用 LCEL 将它们链接起来,如何通过 LangSmith 获得对你创建的链的良好可观察性,以及如何使用 LangServe 部署它们。
这只是你想要成为一名熟练的 AI 工程师所需学习内容的冰山一角。幸运的是,我们还有很多其他资源!
要进一步阅读 LangChain 的核心概念,我们有详细的概念指南。
如果你对这些概念有更具体的问题,请查看以下部分的操作指南:
以及 LangSmith 文档:
构建聊天机器人
概述
我们将通过一个示例来讲解如何设计和实现一个由 LLM 驱动的聊天机器人。这个聊天机器人将能够进行对话并记住之前的互动。
请注意,我们构建的这个聊天机器人只会使用语言模型来进行对话。你可能还在寻找其他几个相关的概念:
对话式 RAG:在外部数据源上启用聊天机器人体验
代理:构建一个可以执行操作的聊天机器人
本教程将涵盖基础知识,这些知识对于上述两个更高级的主题会有所帮助,但如果你愿意,也可以直接跳到那些部分。
概念
以下是我们将要使用的一些高级组件:
-
聊天模型(Chat Models):聊天机器人界面基于消息而不是原始文本,因此更适合使用聊天模型而不是文本 LLM。 -
提示模板(Prompt Templates):简化了组合默认消息、用户输入、聊天历史记录和(可选的)额外检索上下文的提示的过程。 -
聊天历史(Chat History):允许聊天机器人“记住”过去的互动,并在回答后续问题时考虑这些互动。 -
使用 LangSmith 进行调试和追踪:帮助你调试和追踪你的应用程序。
我们将介绍如何将上述组件结合起来,创建一个强大的对话式聊天机器人。
设置
Jupyter Notebook
本指南(以及文档中的大多数其他指南)使用 Jupyter Notebook,并假设读者也是如此。Jupyter Notebook 非常适合学习如何使用 LLM 系统,因为很多时候事情可能会出错(意外输出、API 停止工作等),在交互式环境中进行学习是更好地理解它们的好方法。
这个和其他教程可能最方便在 Jupyter Notebook 中运行。有关如何安装的说明,请参见这里 。
安装
要安装 LangChain,请运行以下命令(二选一):
- 通过 pip 安装
pip install langchain
- 通过 Conda 安装
conda install langchain -c conda-forge
有关更多详细信息,请参见我们的安装指南。
LangSmith
你使用 LangChain 构建的许多应用程序将包含多个步骤,并多次调用 LLM。随着这些应用程序变得越来越复杂,能够检查链或代理内部发生的具体情况变得至关重要。使用 LangSmith 是实现这一目标的最佳方式。
在上面的链接注册后,请确保设置你的环境变量以开始记录追踪信息:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
或者,如果在 Jupyter Notebook 中,你可以使用以下方式设置环境变量:
import getpass
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()